I have been trying, without success, to come up with a cogent explanation of my thoughts on firearms ownership by citizens, government tyranny, those that call for violent revolution, and the costs of police and military intervention. This post is my first attempt to lay out those thoughts in an integrated way. It was prompted by this tweet, though I had been thinking about it before.
The founders of the US thought it was so important to protect the right to keep and bear arms that they listed it in the bill of rights right after freedom of speech (which I agree is more important). It’s common to hear arguments that “only a well-regulated militia” — sometimes interpreted to be the military — is supposed to bear arms, but a review of the prior drafts of the amendment and other statements by those that drafted it makes it clear they meant the whole of the citizenry were the militia, and the constitution was never meant to be interpreted to bar law-abiding citizens the right to keep and bear arms. Recent decisions by the Supreme Court have supported this interpretation. For example, here is an early version proposed by Samuel Adams:
And that the said Constitution be never construed to authorize Congress to infringe the just liberty of the press, or the rights of conscience; or to prevent the people of the United States, who are peaceable citizens, from keeping their own arms. (citation)
Furthermore, it was thought by them that an unarmed citizenry was a citizenry destined to be ruled by tyranny. Wikipedia does a pretty good job of covering his here, but here are some choice quotes:
As civil rulers, not having their duty to the people duly before them, may attempt to tyrannize, and as the military forces which must be occasionally raised to defend our country, might pervert their power to the injury of their fellow citizens, the people are confirmed by the next article in their right to keep and bear their private arms. — Tench Coxe, 1792 (ibid.)
This may be considered as the true palladium of liberty…. The right of self defence is the ï¬rst law of nature: in most governments it has been the study of rulers to conï¬ne this right within the narrowest limits possible. Wherever standing armies are kept up, and the right of the people to keep and bear arms is, under any colour or pretext whatsoever, prohibited, liberty, if not already annihilated, is on the brink of destruction. In England, the people have been disarmed, generally, under the specious pretext of preserving the game : a never failing lure to bring over the landed aristocracy to support any measure, under that mask, though calculated for very different purposes. — St. George Tucker (ibid.)
Abolitionist Lysander Spooner, commenting on bills of rights, stated that the object of all bills of rights is to assert the rights of individuals against the government and that the Second Amendment right to keep and bear arms was in support of the right to resist government oppression, as the only security against the tyranny of government lies in forcible resistance to injustice, for injustice will certainly be executed, unless forcibly resisted. (ibid.)
The tree of liberty must be refreshed from time to time with the blood of patriots and tyrants. — Thomas Jefferson (citation)
People, even those generally sympathetic to Second Amendment rights, rightly point out that the government, with bombers, nuclear weapons, the NSA, and a large standing military could easily put down an insurrection. (Is it time for a violent revolution?). That article does a pretty good job of being realistic in evaluating the pros and cons of such a revolution. I am going to make clear that I think it’s definitely a Bad Idea. That doesn’t mean an armed citizenry is worthless. A very interesting and recent example is the Bundy Standoff and its contrast with the Ferguson unrest. Before I get going let me state that I think Bundy (aside from being a racist and generally a moron) was/is in the wrong. I in no way support his claims.
What I find fascinating is that Bundy and his well-armed supporters were able to raise the cost of the government’s intervention enough to get them to back down. The government can be viewed as a massive, powerful monolith, that doesn’t need the approval of the people to do what it wants, but that’s a mistaken view. The federal government is made of real people with consciences and scruples. Furthermore, if it loses enough public support, and support from a significant portion of the military, it may even leave itself vulnerable to being overthrown. Therefore it’s in the interests of the government and its members not to do things that will widely be perceived as pernicious and overreaching. I think the BLM and Las Vegas PD decided that shooting Bundy and his supporters over some cattle grazing on public lands would have been widely condemned. Without that resistance, I’m fairly certain the BLM would have had their way (which, to be clear, I think was right). I didn’t realize until today that the LVPD actually took steps to tone down their response to Bundy in order to avoid provoking them.
Metro officers deal with large crowds all the time, but nothing like this. The crowd included former military men and ex-cops, people with various motives, their fingers poised just above the triggers of powerful weapons. With so much firepower in so many hands, a small incident could have set off a bloodbath and left nearly two dozen officers dead.
Assist. Sheriff Joe Lombardo:”We were outgunned, outmanned and there would not have been a good result from it.”
I-Team reporter George Knapp: “A lot of scenarios could have played out that would have left a lot of dead officers.”
Assist. Sheriff Joe Lombardo: “If you just have a backfire, somebody pops a firecracker, then it’s over. We’re done. We are going to lose that battle that day.”
Metro pointedly did not allow officers to put on helmets or protective gear for fear it might be seen as a provocation. At the urging of Cliven Bundy, the crowd moved toward the BLM compound. Rhetoric grew more heated, and guns were pointed at officers.
citation
What you see there is that the Bundy protesters made the cost of a powerful, armed showing by the police higher than the police were willing to bear. Contrast that with the events during the protests in Ferguson, MO after the police shooting of Michael Brown.
 Sharpshooter aims at unarmed protesters CC BY 2.0 – Jamelle Bouie – https://www.flickr.com/photos/jbouie/14907066986/in/set-72157646091879339
Sharpshooter aims at unarmed protesters CC BY 2.0 – Jamelle Bouie – https://www.flickr.com/photos/jbouie/14907066986/in/set-72157646091879339
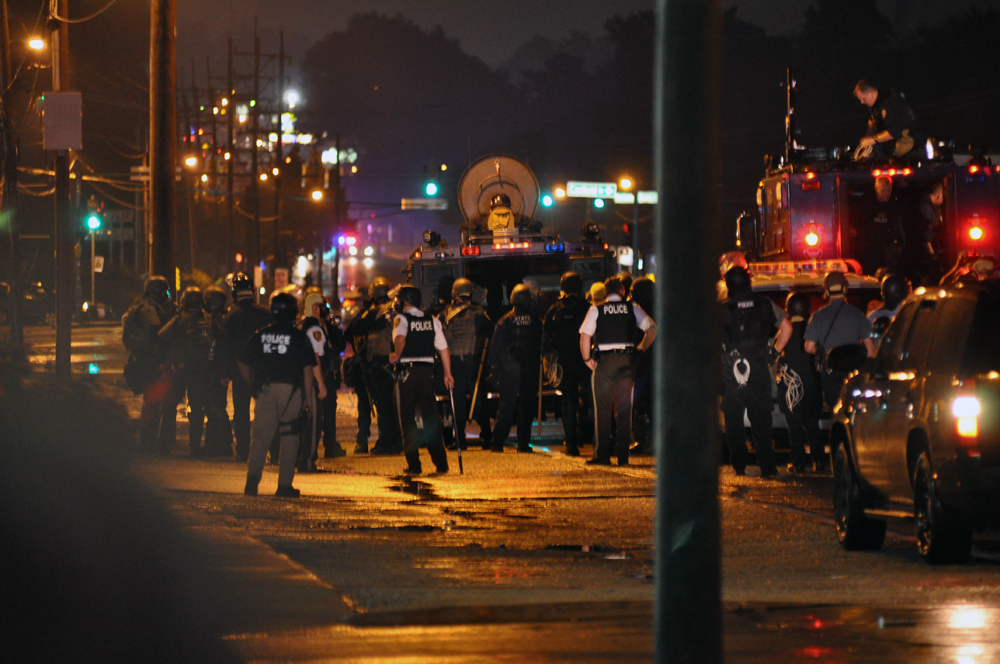 Contingent of police in riot gear with military-type armored vehicles – By Loavesofbread – CC-BY-SA 4.0
Contingent of police in riot gear with military-type armored vehicles – By Loavesofbread – CC-BY-SA 4.0
The Ferguson PD had no such qualms about making a show of force, and it almost certainly agitated the protesters, but for a variety of reasons, most of them were not visibly armed. There’s a whole separate line of reasoning here that the protesters in Ferguson were black, and the folks at the Bundy incident were white, and that’s why the police didn’t crack down on them the same way. I buy that that had some influence, but I don’t think it nearly covers the issue. The quote from LVPD above should make that clear.
What this comes down to, for me, is that even though private ownership of firearms (especially “military-type” firearms that “nobody needs” — which were used by Bundy’s supporters) may not be sufficient for an ex-nihilo overthrow of the government, that private ownership is nonetheless essential to raising the cost of abuse of power by the government.
But in other civilized countries…
There’s another common rebuttal that other countries don’t have the degree of allowed firearm ownership that the USA has, and yet they are able to resolve their problems democratically. All I can say to this is that there are very few democracies that have been around very long on a historical time scale, and we will have to wait and see. Certainly in places like England, which have slowly had their firearms rights (once considered inviolable natural rights) taken away, people have lost much of not only the ability but the right to self-defense. (See Guns and Violence: The English Experience for a fascinating history.) That’s something I’d like to see the USA avoid.

